
언유상씨의 건전한 취미생활
RLHF : Reinforcement learning from Human Feedback란 무엇인가? 본문
RLHF에 대해 공부하다 어려운 부분이 있어 정리를 하게 되었다.
Huggingface의 원문은 다음과 같다.
RLHF : Reinforcement learning from Human Feedback
RLHF's 3 core steps
- Pretraining a language model (LM)
- Gathering data and training a reward model
- Fine-tuning the LM with RL
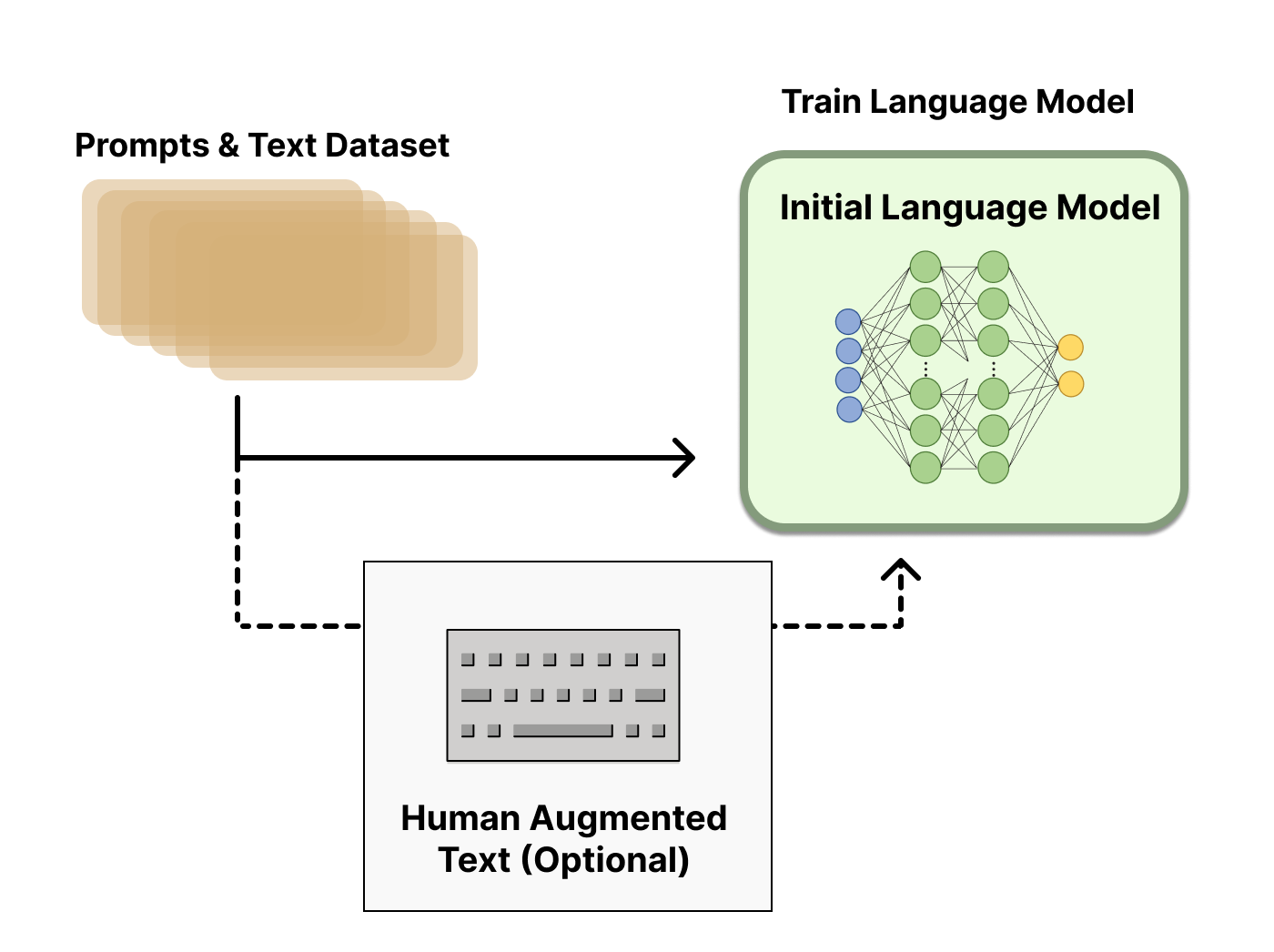
1. Pretraining a language model
다양한 지시에 대답할 수 있는 PLM을 구축한다.
이때, PLM을 추가적인 text나 condition들로 fine-tuning을 진행해도 되지만, 필수적이지는 않다.
2. Gathering data and training a reward model
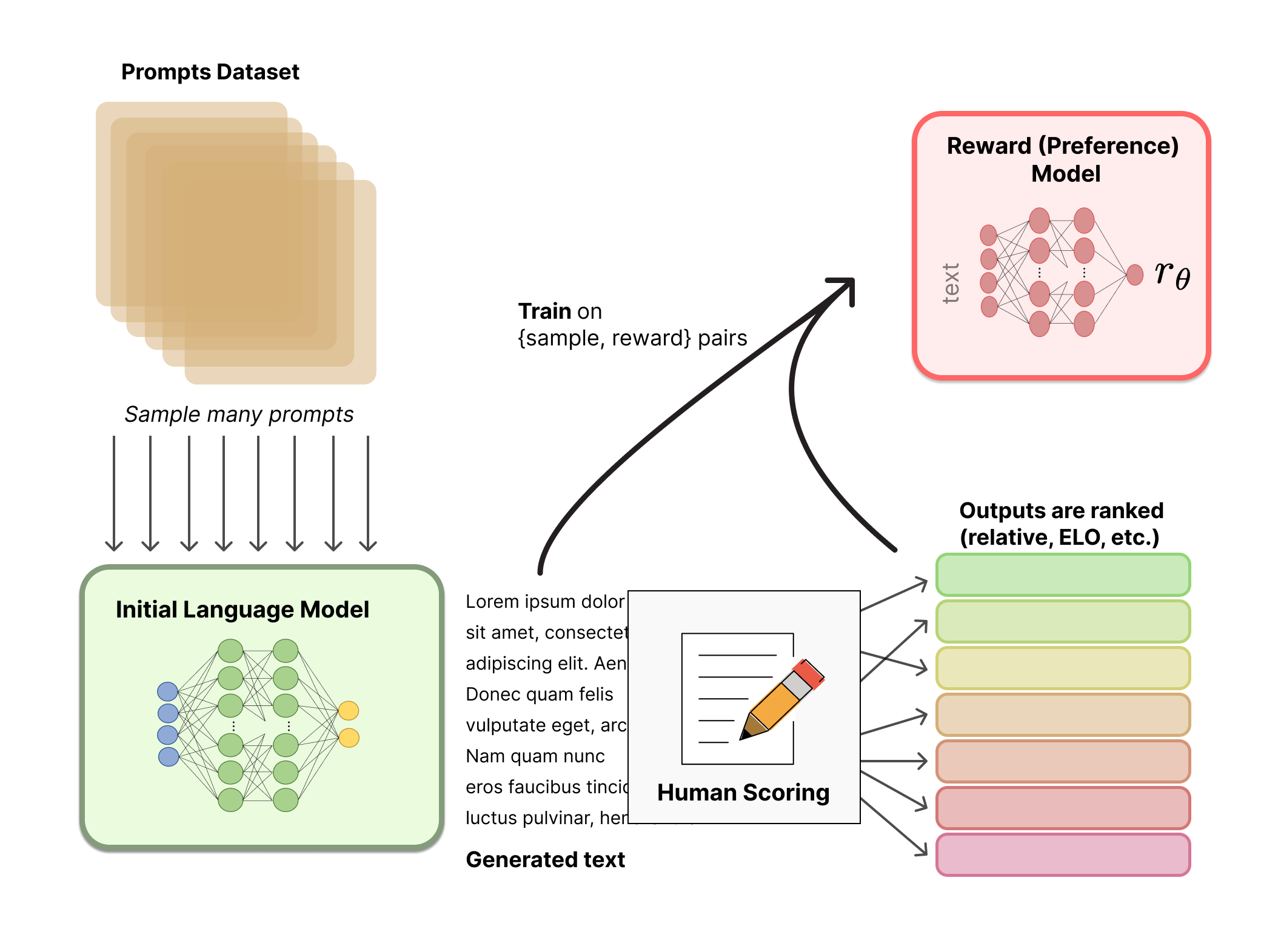
1에서 구축된 PLM이 인간의 선호도를 반영할 수 있도록 Reward Model을 구축한다. RM은 end-to-end LM 일수도 있고, reward만을 반환하는 modular system일 수도 있다.
이때 핵심은 sequence를 입력받아 scalar값 (Rank)를 반환하기만 하면 된다. RM을 위한 LM은 fine-tuning을 진행한 LM이거나, 선호 데이터에 대해 학습된 LM이 될 수 있다.
사전에 정의된 데이터셋을 LM의 input으로 사용하고, LM의 output에 대해 human annotator들이 순위를 결정한다. 순위를 결정하는 좋은 방법 중 하나는, 동일한 프롬프트를 두 개의 LM의 input으로 사용하여 각 LM에서 생성된 output을 비교하는 것이다.
3. Fine-tuning the LM with RL
PLM의 복사본의 일부 혹은 모든 parameter를 Proximal Policy Optimization (PPO)를 통해 fine-tuning을 진행한다. (Policy)
fine-tuning task를 reinforcement problem으로 설정하면 다음과 같다.
Policy : prompt를 받아 text sequence를 반환하는 LM
ex) input : "날씨는 어때?"
output : "오늘은 맑고 따뜻할 예정입니다."
Action space : LM이 사용할 수 있는 모든 어휘에 해당하는 token들
Observation space : 입력 가능한 token sequence의 분포
ex) "오늘 날씨는 ___"
Reward function : RM과 Policy의 변화에 따라 결정됨Prompt x에 대해 text y가 생성된다.
"prompt x + y"의 형태로 RM에 전달되어 y의 선호도 (Rank)를 반환받는다.
최종적으로, Policy의 Action space 내 token들의 분포와 Step1에서 만든 PLM의 Action space 내 token들의 분포를 비교하여 둘 사이에 대한 페널티를 계산하는 방식으로 reinforcement learning이 진행된다.
PLM과 Policy를 비교하는 이유?
PLM의 Action space는 어느 정도의 성능을 보장하므로,
PLM의 Action space에서 크게 벗어나지 않도록 하여 학습의 안정성을 높이고,
Policy의 catastrophic forgetting 가능성을 낮춤
이때, 높은 보상을 받는 쓰레기 텍스트를 생성하는 것을 막기 위해 Action space 내 token들의 분포에 KL divergence를 적용한다.
이로 인해 RL의 update rule은 다음과 같다.
$$r = r_{\theta} - \lambda r_{KL}$$
$$ r_{\theta}$$ : 선호도의 scalar 값
$$ r_{KL}$$: KL divergence를 적용한 페널티
Update rule의 결과값은 PPO의 Policy를 최적화 하는데 쓰이고, 최적화 된 Policy는 인간의 선호도가 반영된 LM이 된다.